

दो साल पहले पूर्व राष्ट्रपति बराक ओबामा ने इसकी घोषणा की थी परिशुद्ध चिकित्सा पहल अपने स्टेट ऑफ द यूनियन संबोधन में। यह पहल "चिकित्सा के नए युग" की आकांक्षा रखती है जहां रोग उपचार को विशेष रूप से प्रत्येक रोगी के आनुवंशिक कोड के अनुरूप बनाया जा सकता है। ![]()
यह कैंसर चिकित्सा में अच्छी तरह प्रतिध्वनित हुआ। मरीज़ पहले से ही उन उपचारों से अपने कैंसर का प्रबंधन कर सकते हैं जो उनके विशेष ट्यूमर में परिवर्तित विशिष्ट जीन को लक्षित करते हैं। उदाहरण के लिए, जीन एचईआर2 के प्रवर्धन के कारण होने वाले एक प्रकार के स्तन कैंसर से पीड़ित महिलाओं का इलाज अक्सर हर्सेप्टिन नामक चिकित्सीय दवा से किया जाता है। चूँकि ये लक्षित उपचार कैंसर कोशिकाओं के लिए विशिष्ट हैं, इसलिए कीमोथेरेपी या विकिरण वाले पारंपरिक कैंसर उपचारों की तुलना में इनके दुष्प्रभाव कम होते हैं।
हालाँकि, अधिकांश कैंसर रोगियों के लिए ऐसे उपचार उपलब्ध नहीं हैं। कई कैंसरों में, कैंसर के लिए जिम्मेदार विशिष्ट आनुवंशिक परिवर्तन अज्ञात रहते हैं। व्यक्तिगत कैंसर उपचार बनाने के लिए, हमें कार्यात्मक आनुवंशिक परिवर्तनों के बारे में अधिक जानना चाहिए।
कैंसर आनुवंशिकी पर डेटा तेजी से बढ़ने के साथ, गणित और सांख्यिकी अब इस डेटा में छिपे पैटर्न को अनलॉक करने में मदद कर सकते हैं ताकि उन जीनों को ढूंढा जा सके जो किसी व्यक्ति के कैंसर के लिए जिम्मेदार हैं। इस ज्ञान के साथ, चिकित्सक उचित उपचार का चयन कर सकते हैं जो व्यक्तिगत रोगियों के लिए उपचारों को वैयक्तिकृत करने के लिए इन जीनों की क्रिया को अवरुद्ध करते हैं। मेरे शोध का उद्देश्य कैंसर में सटीक चिकित्सा में सुधार करना है - उन्हीं तरीकों पर निर्माण करके जिनका उपयोग नेटफ्लिक्स मूवी रेटिंग्स में पैटर्न खोजने के लिए किया गया है।
डेटा के माध्यम से छान-बीन करना
आज, कैंसर आनुवंशिकी डेटा तक अभूतपूर्व सार्वजनिक पहुंच है। ये डेटा उदार रोगियों से आते हैं जो अनुसंधान के लिए अपने ट्यूमर के नमूने दान करते हैं। इसके बाद वैज्ञानिक मानव जीनोम में 20,000 जीनों में से प्रत्येक में उत्परिवर्तन और गतिविधि को मापने के लिए अनुक्रमण तकनीक लागू करते हैं।

ये सभी डेटा इसका प्रत्यक्ष परिणाम हैं मानव जीनोम परियोजना 2003 में। उस परियोजना ने स्वस्थ मानव डीएनए बनाने वाले सभी जीनों के अनुक्रम को निर्धारित किया। उस परियोजना के पूरा होने के बाद से, मानव जीनोम को अनुक्रमित करने की लागत बढ़ गई है हर साल आधे से भी ज्यादा कम हो गया, में वर्णित कंप्यूटिंग शक्ति की वृद्धि को पार कर गया मूर की विधि. यह लागत में कमी अनुसंधानों को कैंसर रोगियों से अभूतपूर्व आनुवंशिकी डेटा एकत्र करने में सक्षम बनाती है।
दुनिया भर में कैंसर आनुवंशिकी पर किए गए अधिकांश वैज्ञानिक अध्ययन अपना डेटा यूएस नेशनल इंस्टीट्यूट ऑफ हेल्थ (एनआईएच) नेशनल लाइब्रेरी ऑफ मेडिसिन द्वारा प्रदान किए गए एक केंद्रीकृत, सार्वजनिक डेटाबेस में जारी करते हैं। एनआईएच राष्ट्रीय कैंसर संस्थान और राष्ट्रीय मानव जीनोम अनुसंधान संस्थान ने भी एक परियोजना के माध्यम से 11,000 कैंसर प्रकारों में 33 से अधिक ट्यूमर से आनुवंशिक डेटा स्वतंत्र रूप से जारी किया है। कैंसर जीनोम एटलस।
प्रत्येक जैविक क्रिया - भोजन से ऊर्जा निकालने से लेकर घाव भरने तक - जीन के विभिन्न संयोजनों में गतिविधि के परिणामस्वरूप होती है। कैंसर उन जीनों को हाईजैक कर लेता है जो लोगों को वयस्कता तक बढ़ने में सक्षम बनाते हैं और जो शरीर को प्रतिरक्षा प्रणाली से बचाते हैं। शोधकर्ता इन्हें डब करते हैं "कैंसर के लक्षण।" यह तथाकथित जीन विकृति ट्यूमर को अनियंत्रित रूप से बढ़ने और मूल ट्यूमर साइट से दूर के अंगों में मेटास्टेस बनाने में सक्षम बनाती है।
शोधकर्ता प्रत्येक ट्यूमर प्रकार के लिए जिम्मेदार जीन परिवर्तनों के सेट को खोजने के लिए इन सार्वजनिक डेटा का सक्रिय रूप से उपयोग कर रहे हैं। लेकिन यह समस्या इतनी सरल नहीं है कि प्रत्येक ट्यूमर में एक एकल विकृत जीन की पहचान की जाए। मानव जीनोम में 20,000 जीनों में से यदि हजारों नहीं तो सैकड़ों, कैंसर में अनियंत्रित होते हैं। प्रत्येक रोगी के ट्यूमर में विकृत जीनों का समूह अलग-अलग होता है, आमतौर पर पुन: उपयोग किए जाने वाले जीनों के छोटे सेट प्रत्येक कैंसर हॉलमार्क को सक्षम करते हैं।
सटीक दवा प्रत्येक रोगी के ट्यूमर में जैविक कार्य के लिए जिम्मेदार अनियमित जीन के छोटे समूहों को खोजने पर निर्भर करती है। लेकिन, विभिन्न संदर्भों में जीन के कई जैविक कार्य हो सकते हैं। इसलिए, शोधकर्ताओं को "अतिव्यापी" जीनों के एक सेट को उजागर करना होगा जो कैंसर रोगियों के एक समूह में सामान्य कार्य करते हैं।
जीन स्थिति को कार्य से जोड़ने के लिए जटिल गणित और अपार कंप्यूटिंग शक्ति की आवश्यकता होती है। यह ज्ञान उन उपचारों के परिणाम की भविष्यवाणी करने के लिए आवश्यक है जो इन जीनों के कार्य को अवरुद्ध कर देंगे। तो, हम मरीजों के लिए व्यक्तिगत परिणामों की भविष्यवाणी करने के लिए उन अतिव्यापी सुविधाओं को कैसे उजागर कर सकते हैं?
नेटफ्लिक्स हमें क्या सिखा सकता है
सौभाग्य से हमारे लिए, कंप्यूटर विज्ञान में यह समस्या पहले ही हल हो चुकी है। इसका उत्तर तकनीकों का एक वर्ग है जिसे "मैट्रिक्स फ़ैक्टराइज़ेशन" कहा जाता है - और संभवतः आप पहले से ही अपने रोजमर्रा के जीवन में इन तकनीकों के साथ बातचीत कर चुके हैं।
2009 में, नेटफ्लिक्स ने एक चुनौती रखी प्रत्येक नेटफ्लिक्स उपयोगकर्ता के लिए मूवी रेटिंग को वैयक्तिकृत करने के लिए। नेटफ्लिक्स पर, प्रत्येक उपयोगकर्ता के पास अलग-अलग फिल्मों की रेटिंग का एक अलग सेट होता है। हालाँकि दो उपयोगकर्ताओं की फिल्मों में रुचि समान हो सकती है, लेकिन विशिष्ट शैलियों में उनकी रुचि काफी भिन्न हो सकती है। इसलिए, आप समान उपयोगकर्ताओं की रेटिंग की तुलना पर भरोसा नहीं कर सकते।
इसके बजाय, एक मैट्रिक्स फ़ैक्टराइज़ेशन एल्गोरिदम उपयोगकर्ताओं के एक छोटे समूह के बीच समान रेटिंग वाली फिल्में ढूंढता है। प्रत्येक फिल्म के लिए उपयोगकर्ताओं का समूह अलग-अलग होगा। कंप्यूटर प्रत्येक उपयोगकर्ता को उनके व्यक्तिगत स्वाद के आधार पर अलग-अलग हद तक फिल्मों के समूह से जोड़ता है। उपयोगकर्ताओं के बीच संबंधों को "पैटर्न" कहा जाता है। ये पैटर्न डेटा से सीखे जाते हैं, और अकेले फिल्म शैली द्वारा अप्रत्याशित सामान्य रैंकिंग मिल सकती है - उदाहरण के लिए, उपयोगकर्ता किसी विशेष निर्देशक या अभिनेता के लिए प्राथमिकता साझा कर सकते हैं।
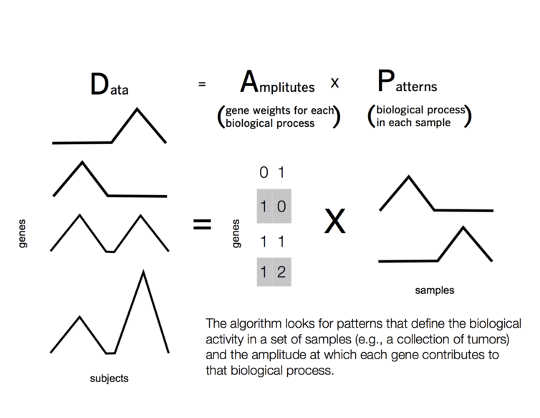 जेनेवीव स्टीन-ओ'ब्रायन, सीसी द्वारा
जेनेवीव स्टीन-ओ'ब्रायन, सीसी द्वारा
यही प्रक्रिया कैंसर में भी काम कर सकती है। इस मामले में, जीन डिसरेग्यूलेशन की माप मूवी रेटिंग, मूवी शैलियों से लेकर जैविक कार्य और उपयोगकर्ताओं के रोगियों के ट्यूमर के अनुरूप होती है। कंप्यूटर जीन विकृति में पैटर्न खोजने के लिए रोगी के ट्यूमर की खोज करता है जो प्रत्येक ट्यूमर में घातक जैविक कार्य का कारण बनता है।
फिल्मों से लेकर ट्यूमर तक
मूवी रेटिंग और कैंसर आनुवांशिकी के बीच सादृश्य विवरण में टूट जाता है। जब तक वे नाबालिग न हों, नेटफ्लिक्स उपयोगकर्ताओं को उनके द्वारा देखी जाने वाली फिल्में देखने पर कोई रोक नहीं है। लेकिन, इसके बजाय हमारा शरीर किसी एक कार्य के लिए उपयोग किए जाने वाले जीन की संख्या को कम करना पसंद करता है। जीनों के बीच भी पर्याप्त अतिरेक हैं। किसी कोशिका की सुरक्षा के लिए, एक सामान्य कार्य को पूरा करने के लिए एक जीन आसानी से दूसरे जीन का स्थान ले सकता है। कैंसर में जीन के कार्य और भी अधिक जटिल होते हैं। ट्यूमर भी अत्यधिक जटिल होते हैं और तेजी से विकसित होते हैं, जो कैंसर कोशिकाओं और आसन्न स्वस्थ अंग के बीच यादृच्छिक बातचीत पर निर्भर करते हैं।
इन जटिलताओं को ध्यान में रखते हुए, हमने एक मैट्रिक्स फ़ैक्टराइज़ेशन दृष्टिकोण विकसित किया है जिसे कहा जाता है पैटर्न सेट में समन्वित जीन गतिविधि - या संक्षेप में CoGAPS. हमारा एल्गोरिदम प्रत्येक ट्यूमर के पैटर्न में यथासंभव कम से कम जीनों को शामिल करके जीव विज्ञान के न्यूनतमवाद को ध्यान में रखता है।
विभिन्न जीन एक दूसरे का स्थानापन्न भी हो सकते हैं, प्रत्येक जीन एक अलग संदर्भ में समान कार्य करते हैं। इसका हिसाब देने के लिए, CoGAPS एक साथ जीन फ़ंक्शन के तथाकथित "पैटर्न" के लिए एक आंकड़े का अनुमान लगाता है। यह हमें ट्यूमर में प्रत्येक जैविक कार्य में उपयोग किए जाने वाले प्रत्येक जीन की संभावना की गणना करने की अनुमति देता है।
उदाहरण के लिए, कई मरीज़ कोलोरेक्टल, अग्नाशय, फेफड़े और मौखिक कैंसर में जीवित रहने के लिए सेटुक्सिमैब नामक एक लक्षित चिकित्सीय दवा लेते हैं। हमारे हालिया काम में पाया गया कि ये पैटर्न कैंसर कोशिकाओं में जीन फ़ंक्शन को अलग कर सकते हैं जो लक्षित चिकित्सीय एजेंट सेतुक्सिमैब पर प्रतिक्रिया नहीं करते हैं।
भविष्य
दुर्भाग्य से, जीन को लक्षित करने वाली कैंसर चिकित्सा आमतौर पर किसी मरीज की बीमारी का इलाज नहीं कर सकती है। वे केवल कुछ वर्षों तक प्रगति में देरी कर सकते हैं। अधिकांश मरीज़ फिर से ट्यूमर के शिकार हो जाते हैं, जो उपचार के प्रति प्रतिक्रियाशील नहीं रह जाते हैं।
हमारा अपना हालिया काम पाया गया कि जो पैटर्न सेतुक्सिमैब के प्रति प्रतिक्रियाशील कोशिकाओं में जीन फ़ंक्शन को अलग करते हैं उनमें वही जीन शामिल होते हैं जो प्रतिरोध को जन्म देते हैं। उभरती इम्यूनोथेरेपी आशाजनक हैं और कुछ कैंसर का इलाज करती प्रतीत होती हैं। फिर भी, बहुत बार, इन उपचारों वाले मरीज़ भी दोबारा बीमार पड़ जाते हैं। उपचार के बाद कैंसर आनुवंशिकी को ट्रैक करने वाला नया डेटा यह निर्धारित करने के लिए आवश्यक है कि मरीज़ अब प्रतिक्रिया क्यों नहीं देते हैं।
इन आंकड़ों के साथ, कैंसर जीव विज्ञान को वैज्ञानिकों की एक नई पीढ़ी की भी आवश्यकता है जो दवा प्रतिरोध में समय के साथ होने वाले आनुवंशिक परिवर्तनों को निर्धारित करने के लिए गणित और सांख्यिकी को जोड़ सकें। गणित के अन्य क्षेत्रों में, कंप्यूटर प्रोग्राम दीर्घकालिक परिणामों का पूर्वानुमान लगाने में सक्षम हैं। इन मॉडलों का उपयोग आमतौर पर मौसम की भविष्यवाणी और निवेश रणनीतियों में किया जाता है।
इन क्षेत्रों में और मेरा अपना पिछला शोध, हमने पाया है कि बड़े डेटासेट से मॉडल के अपडेट - जैसे मौसम के मामले में उपग्रह डेटा - दीर्घकालिक पूर्वानुमानों में सुधार करते हैं। हम सभी ने इन अद्यतनों का प्रभाव देखा है, जैसे-जैसे हम तूफान के करीब पहुँचते हैं, मौसम की भविष्यवाणियाँ बेहतर होती जाती हैं।
जिस तरह इस्तेमाल किए गए कंप्यूटर विज्ञान के उपकरणों को फिल्म की सिफारिशों और कैंसर दोनों के लिए अनुकूलित किया जा सकता है, उसी तरह कम्प्यूटेशनल वैज्ञानिकों की भावी पीढ़ी सटीक चिकित्सा के लिए विभिन्न क्षेत्रों से भविष्यवाणी उपकरण अपनाएगी। अंततः, इन कम्प्यूटेशनल उपकरणों के साथ, हम चिकित्सा के प्रति ट्यूमर की प्रतिक्रिया की भविष्यवाणी करने की उम्मीद करते हैं जैसे हम आमतौर पर मौसम की भविष्यवाणी करते हैं, और शायद अधिक विश्वसनीय रूप से।
के बारे में लेखक
एलाना फर्टिग, ऑन्कोलॉजी बायोस्टैटिस्टिक्स और बायोइनफॉरमैटिक्स के सहायक प्रोफेसर, जॉन्स हॉपकिन्स विश्वविद्यालय
यह आलेख मूलतः पर प्रकाशित हुआ था वार्तालाप। को पढ़िए मूल लेख.
संबंधित पुस्तकें
at इनरसेल्फ मार्केट और अमेज़न



















