

अपने सार्वजनिक लॉन्च से 10 वर्ष पहले, ट्विटर का इस्तेमाल दोस्तों के बीच एक सोशल नेटवर्किंग मंच के रूप में किया गया है, स्मार्टफोन उपयोगकर्ताओं के लिए एक त्वरित संदेश सेवा और निगमों और राजनेताओं के लिए एक प्रचार उपकरण।
लेकिन यह शोधकर्ताओं और वैज्ञानिकों के लिए भी डेटा का एक अनमोल स्रोत रहा है - मेरे जैसे - जो अध्ययन करना चाहते हैं कि जटिल सामाजिक प्रणालियों के भीतर मनुष्य कैसे महसूस करता है और कार्य करता है।
ट्वीट्स का विश्लेषण करके, हम नियंत्रित प्रयोगशाला प्रयोगों के बाहर "जंगली में" लाखों लोगों के सामाजिक संबंधों पर डेटा का निरीक्षण और एकत्र करने में सक्षम हैं।
यह हमें निगरानी के लिए उपकरण विकसित करने में सक्षम है बड़ी आबादी की सामूहिक भावनाएं, खोजें संयुक्त राज्य अमेरिका में सबसे ख़ूबसूरत जगह और अन्य जानकारी जो बॉलीवुड और सेलिब्रिटी हस्तियाो के साथ संबंधत हो ।
तो, बिल्कुल कैसे, ट्विटर ने कम्प्यूटेशनल सामाजिक वैज्ञानिकों के लिए इस तरह के एक अद्वितीय संसाधन बनवाए? और हमें क्या पता चला है?

चहचहाना के शोधकर्ताओं के लिए सबसे बड़ा उपहार
जुलाई 15, 2006, Twittr (जैसा कि तब जाना जाता था) सार्वजनिक रूप से शुभारंभ "मोबाइल सेवा जो दोस्तों के समूहों को एसएमएस के साथ यादृच्छिक विचारों को बाउंस करने में मदद करता है।" के रूप में, मुफ्त 140- समूह समूह ग्रंथों को भेजने की क्षमता ने प्लेटफ़ॉर्म का उपयोग करने के लिए कई प्रारंभिक अपनाने वाले (मेरे शामिल किए)
समय के साथ, उपयोगकर्ताओं की संख्या विस्फोट: 20 से 2009 से 200 लाख 2012 और 310 लाख में आज सीधे दोस्तों के साथ संवाद करने के बजाय, उपयोगकर्ता बस अपने अनुयायियों को बताएंगे कि उन्होंने कैसा महसूस किया, समाचारों को सकारात्मक या नकारात्मक रूप से जवाब दिया, या चुटकुले को दरार कर दिया।
शोधकर्ताओं के लिए, ट्विटर का सबसे बड़ा उपहार खुली डेटा की बड़ी मात्रा का प्रावधान रहा है। चहचहाना सबसे पहले प्रमुख सामाजिक नेटवर्क में से एक था, जिसे अनुप्रयोग प्रोग्रामिंग इंटरफेस (एपीआई) कहा जाता है, जो कि शोधकर्ताओं ने विशिष्ट प्रकार के ट्वीट्स (जैसे कि कुछ शब्द शामिल होने वाले ट्वीट्स) के लिए ट्विटर से पूछे, साथ ही उपयोगकर्ताओं के बारे में जानकारी के माध्यम से डेटा नमूने प्रदान करने में एक था। ।
इससे इस डेटा का शोषण करने वाले अनुसंधान परियोजनाओं का विस्फोट हुआ। आज, "ट्विटर" के लिए एक Google विद्वान खोज "फेसबुक" के लिए पांच लाख के मुकाबले 60 लाख हिट का उत्पादन करती है। अंतर विशेष रूप से दिया गया है कि फेसबुक ने लगभग चहचहाना के रूप में पांच गुना ज्यादा उपयोगकर्ता (और दो साल पुरानी है)।
चहचहाना की उदार डेटा नीति ने निस्संदेह कंपनी के लिए कुछ उत्कृष्ट मुफ्त प्रचार का नेतृत्व किया, क्योंकि मुख्यधारा के मीडिया द्वारा दिलचस्प वैज्ञानिक अध्ययनों को मिला।
खुशी और स्वास्थ्य का अध्ययन करना
पारंपरिक जनगणना के आंकड़ों के साथ धीमी और महंगी इकट्ठा करने के लिए, खुली डेटा फीड्स जैसे ट्विटर में बड़ी आबादी में परिवर्तन देखने के लिए वास्तविक-समय की खिड़की उपलब्ध कराने की क्षमता होती है।
विश्वविद्यालय के वरमोंट के कम्प्यूटेशनल स्टोरी लैब 2006 में स्थापित किया गया था और संबंधित गणित, समाजशास्त्र और भौतिकी में पढ़ाई समस्याओं। 2008 के बाद से, स्टोरी लैब ने ट्विटर के "गार्डनहोस" फीड के माध्यम से अरबों ट्वीट्स एकत्र किए हैं, जो एक एपीआई है जो वास्तविक समय में सभी सार्वजनिक ट्वीट्स के 10 प्रतिशत का यादृच्छिक नमूना बनाता है।
मैंने कम्प्यूटेशनल स्टोरी लैब में तीन साल बिताए और भाग्यशाली था कि इस डेटा का उपयोग करके कई रोचक अध्ययनों का हिस्सा बनें। उदाहरण के लिए, हमने एक विकसित किया hedonometer जो वास्तविक समय में ट्विट्टरस्फेयर की खुशी को मापता है। स्मार्टफ़ोन्स से भेजे गए भौगोलिक ट्वीट्स पर ध्यान केंद्रित करके, हम सक्षम थे नक्शा संयुक्त राज्य अमेरिका में सबसे ख़ूबसूरत जगह शायद आश्चर्यजनक रूप से, हमने पाया हवाई सबसे खुशहाल राज्य और शराब बनाने वाले नापा सबसे खुशी का शहर है 2013 के लिए।
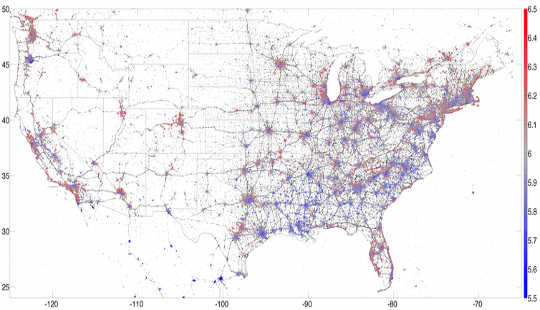 13 लाख से जीयूओएलओकेटेड अमेरिका के ट्विस्ट्स का एक नक्शा, खुशी से रंग दिया गया है, लाल से संकेत मिलता है और नीले रंग का उदासी का संकेत है। वन PLOS, लेखक प्रदान की गईइन अध्ययनों के गहन अनुप्रयोग थे: जनसांख्यिकी के साथ चहचहाना शब्द के उपयोग को सम्बन्ध करते हुए हमें शहरों में सामाजिक आर्थिक पैटर्न को समझने में मदद मिली। उदाहरण के लिए, हम स्वास्थ्य के कारकों जैसे मोटापे के साथ शब्द उपयोग को लिंक कर सकते हैं, इसलिए हमने एक का निर्माण किया lexicocalorimeter सोशल मीडिया पोस्ट की "कैलोरी कंटेंट" को मापने के लिए किसी विशेष क्षेत्र से ट्वीट्स जो कि उच्च कैलोरी खाद्य पदार्थों का उल्लेख करते हैं, उस क्षेत्र की "कैलोरी सामग्री" में वृद्धि हुई, जबकि टिविट्स ने व्यायाम गतिविधियों का उल्लेख करते हुए हमारी मीट्रिक घटा दी हमने पाया कि यह सरल उपाय अन्य स्वास्थ्य और अच्छी तरह से मैट्रिक्स के साथ संबद्ध। दूसरे शब्दों में, ट्वीट्स एक शहर या क्षेत्र के समग्र स्वास्थ्य के समय में एक विशेष क्षण में हमें स्नैपशॉट देने में सक्षम थे।
13 लाख से जीयूओएलओकेटेड अमेरिका के ट्विस्ट्स का एक नक्शा, खुशी से रंग दिया गया है, लाल से संकेत मिलता है और नीले रंग का उदासी का संकेत है। वन PLOS, लेखक प्रदान की गईइन अध्ययनों के गहन अनुप्रयोग थे: जनसांख्यिकी के साथ चहचहाना शब्द के उपयोग को सम्बन्ध करते हुए हमें शहरों में सामाजिक आर्थिक पैटर्न को समझने में मदद मिली। उदाहरण के लिए, हम स्वास्थ्य के कारकों जैसे मोटापे के साथ शब्द उपयोग को लिंक कर सकते हैं, इसलिए हमने एक का निर्माण किया lexicocalorimeter सोशल मीडिया पोस्ट की "कैलोरी कंटेंट" को मापने के लिए किसी विशेष क्षेत्र से ट्वीट्स जो कि उच्च कैलोरी खाद्य पदार्थों का उल्लेख करते हैं, उस क्षेत्र की "कैलोरी सामग्री" में वृद्धि हुई, जबकि टिविट्स ने व्यायाम गतिविधियों का उल्लेख करते हुए हमारी मीट्रिक घटा दी हमने पाया कि यह सरल उपाय अन्य स्वास्थ्य और अच्छी तरह से मैट्रिक्स के साथ संबद्ध। दूसरे शब्दों में, ट्वीट्स एक शहर या क्षेत्र के समग्र स्वास्थ्य के समय में एक विशेष क्षण में हमें स्नैपशॉट देने में सक्षम थे।
चहचहाना डेटा की समृद्धि का उपयोग करते हुए, हम भी सक्षम हो गए हैं अभूतपूर्व विस्तार में लोगों के दैनिक आंदोलन पैटर्न देखें। मानव गतिशीलता के पैटर्न को समझना, बदले में, बीमारी के मॉडल को बदलने की क्षमता है, नए क्षेत्र को खोलना डिजिटल महामारी विज्ञान.
अन्य अध्ययनों के लिए, हमने देखा कि क्या यात्रियों की तुलना में ट्विटर पर अधिक खुशी है कि वे घर पर रहने वाले लोगों से (उत्तर: वे करते हैं) और अगर खुश व्यक्ति सामाजिक नेटवर्क में एक साथ रहना पसंद करते हैं (फिर से, वे करते हैं)। वास्तव में, सकारात्मकता को भाषा में बेक किया जाता है, इस अर्थ में कि नकारात्मक शब्दों की तुलना में हमारे पास अधिक सकारात्मक शब्द हैं। यह सिर्फ ट्विटर पर नहीं बल्कि विभिन्न मीडिया (जैसे, किताबें, फिल्मों और अख़बारों) और भाषाओं के विभिन्न प्रकारों में था।
ये अध्ययन - और दुनिया भर से हजारों अन्य जैसे - संभवतः ट्विटर के लिए संभव है
अगले 10 वर्ष
तो हम अगले 10 वर्षों में ट्विटर से क्या सीख सकते हैं?
सबसे रोमांचक काम में से कुछ में वर्तमान में गणितीय मॉडल के साथ सोशल मीडिया के डेटा को जोड़ने से जनसंख्या स्तर की घटनाओं का अनुमान लगाया जाता है जैसे कि रोग फैलने संशोधकों ने इन्फ्लूएंजा की भविष्यवाणी के लिए ट्विटर डेटा के साथ रोग मॉडल को बढ़ाने में कुछ सफलता हासिल की है, विशेष रूप से FluOutlook पूर्वोत्तर विश्वविद्यालय और वैज्ञानिक इंटरचेंज के लिए संस्थान द्वारा विकसित मंच
फिर भी, कई चुनौतियां रहती हैं सोशल मीडिया डेटा बहुत कम "सिग्नल टू शोर रेशियो" से पीड़ित है। दूसरे शब्दों में, एक विशेष अध्ययन के लिए प्रासंगिक ट्वीट्स अक्सर अप्रासंगिक "शोर" से डूब गए हैं।
इसलिए, हमें लगातार क्या डब किया गया है के बारे में जागरूक होना चाहिए "बड़ा डेटा हर्बिस"जब नए तरीकों के विकास और हमारे परिणामों के अतिसंवेदनशील न हों इसके साथ जुड़े इन आंकड़ों से व्याख्यात्मक "ग्लास-बॉक्स" भविष्यवाणियां तैयार करने का उद्देश्य होना चाहिए ("ब्लैक-बॉक्स" पूर्वानुमान के विपरीत, जिसमें एल्गोरिद्म छिपा हुआ है या साफ़ नहीं है)।
सोशल मीडिया डेटा अक्सर (काफी) छोटे, अनपेक्षित नमूना व्यापक आबादी का। शोधकर्ताओं के लिए बड़ी चुनौतियों में से एक यह पता लगा रहा है कि सांख्यिकीय मॉडल में इस तरह के skewed डेटा के लिए कैसे खाते हैं। जबकि अधिक लोग सोशल मीडिया हर साल उपयोग कर रहे हैं, हमें इस डेटा में पूर्वाग्रहों को समझने की कोशिश करना जारी रखना चाहिए। उदाहरण के लिए, डेटा अभी भी पुरानी आबादी की कीमत पर युवा व्यक्तियों को प्रस्तुत करते हैं।
बेहतर पूर्वाग्रह सुधार विधियों के विकास के बाद ही शोधकर्ता ट्वीट्स से पूरी तरह से आश्वस्त भविष्यवाणियां करने में सक्षम होंगे।
के बारे में लेखक
लेविस मिशेल, एप्लाइड गणित में व्याख्याता, एडीलेड विश्वविद्यालय
यह आलेख मूलतः पर प्रकाशित हुआ था वार्तालाप। को पढ़िए मूल लेख.
संबंधित पुस्तकें
at इनरसेल्फ मार्केट और अमेज़न




















